Natural Language Processing (NLP)
Understanding BERT Architecture: A Beginner's Friendly Explanation
3:53 AM UTC · December 23, 2024 · 8 min read
Rajesh Kapoor
Data scientist specializing in natural language processing and AI ethics.
Data scientist specializing in natural language processing and AI ethics.
BERT stands for Bidirectional Encoder Representations from Transformers. It is a revolutionary natural language processing (NLP) model developed by Google.
BERT was introduced in 2018. It marked a significant advancement in the field of NLP.
BERT's importance lies in its ability to understand the context of words in a sentence. Traditional language models process text sequentially, either from left-to-right or right-to-left.
BERT, however, looks at the entire sequence of words at once. This allows it to capture the full context of a word by considering both its preceding and succeeding words, revolutionizing the accuracy of language understanding.
Bidirectional training is a key innovation of BERT. It means the model is trained to understand the context of a word based on all of its surrounding words, both to the left and to the right.
This is different from previous models that only looked at words in one direction. This allows for a deeper understanding of language context and flow.
The Transformer architecture, introduced in the paper "Attention is All You Need", is the foundation of BERT. It consists of an encoder and a decoder, but BERT primarily utilizes the encoder.
The encoder reads the text input. The decoder produces a prediction for the task.
Self-attention is a crucial component of the Transformer architecture. It allows the model to weigh the importance of each word in relation to all other words in the sentence.
This mechanism enables BERT to understand the relationships between words, even if they are far apart. For example, in the sentence "The animal didn't cross the street because it was too tired", self-attention helps BERT understand that "it" refers to "the animal".
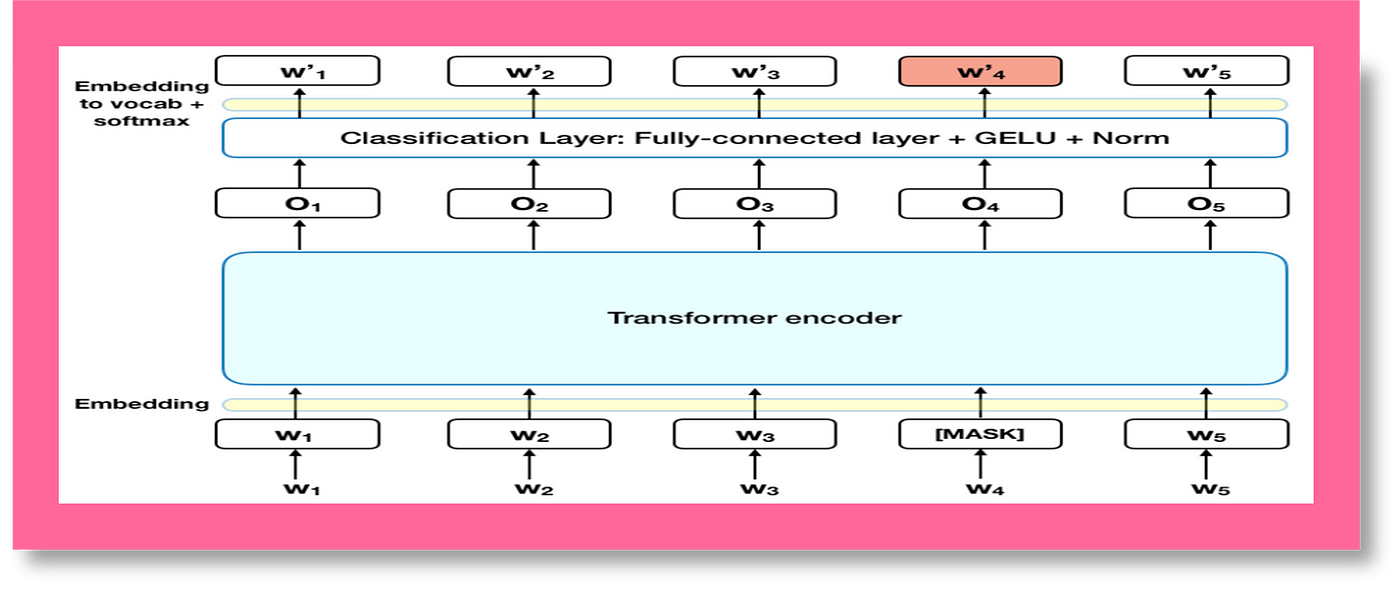
MLM is a training technique used in BERT where 15% of the words in a sentence are replaced with a [MASK] token. The model then attempts to predict the original words based on the surrounding context.
This process helps BERT learn the relationships between words. You can learn more about this technique in the original BERT paper.
NSP is another training technique used in BERT. The model is given pairs of sentences and learns to predict if the second sentence follows the first in the original text.
This helps BERT understand the relationships between sentences. It is useful for tasks like question answering and natural language inference.
Traditional word embeddings, like Word2Vec, assign a fixed vector representation to each word. BERT, on the other hand, generates contextual word embeddings.
This means the representation of a word changes based on its context in a sentence. For example, the word "bank" would have different embeddings in "river bank" and "money bank".
BERT offers several advantages over traditional NLP models. Its bidirectional training allows for a deeper understanding of context.
Its use of the Transformer architecture and self-attention mechanism enables it to capture complex relationships between words. Also, its pre-training on a massive dataset allows it to be fine-tuned for specific tasks with relatively small amounts of data.
BERT can be used for sentiment analysis. It can determine whether a piece of text expresses a positive, negative, or neutral sentiment.
This is achieved by fine-tuning BERT on a dataset of labeled text. It is labeled with sentiment scores.
BERT can also be used for named entity recognition (NER). This involves identifying and classifying named entities in text, such as persons, organizations, and locations.
Fine-tuning BERT on a dataset of annotated text can achieve state-of-the-art results in NER. For example, it can be trained to identify the various types of entities (Person, Organization, Date, etc) that appear in the text.
BERT excels at question answering tasks. Given a question and a passage of text, BERT can identify the answer within the text.
This is done by training BERT to predict the start and end positions of the answer within the passage. It is similar to how software receives a question regarding a text sequence and is required to mark the answer in the sequence.
Traditional NLP models often rely on feature engineering. Linguistic experts manually create features that capture relevant information from the text.
BERT, as a deep learning model, automatically learns features from the data. It is during the pre-training process.
BERT has achieved state-of-the-art results on various NLP benchmarks. These benchmarks include GLUE (General Language Understanding Evaluation), SQuAD (Stanford Question Answering Dataset), and SWAG (Situations With Adversarial Generations).
These benchmarks evaluate models on tasks like natural language inference, question answering, and commonsense reasoning. For more details, see section 4 of the BERT paper.
Research has shown that BERT outperforms traditional models on many NLP tasks. For instance, on the SQuAD v1.1 dataset, BERT achieved an F1 score of 93.2, surpassing human performance.
This demonstrates its superior ability to understand and reason about text. The fact that it’s approachable and allows fast fine-tuning will likely allow a wide range of practical applications in the future.
To use BERT, you first need to set up your environment. This typically involves installing Python and libraries like TensorFlow or PyTorch.
You can also use the Hugging Face Transformers library. It provides a simple interface for working with BERT and other Transformer models.
Fine-tuning BERT involves training the pre-trained model on a specific task with a labeled dataset. This process updates the model's weights to optimize its performance on the new task.
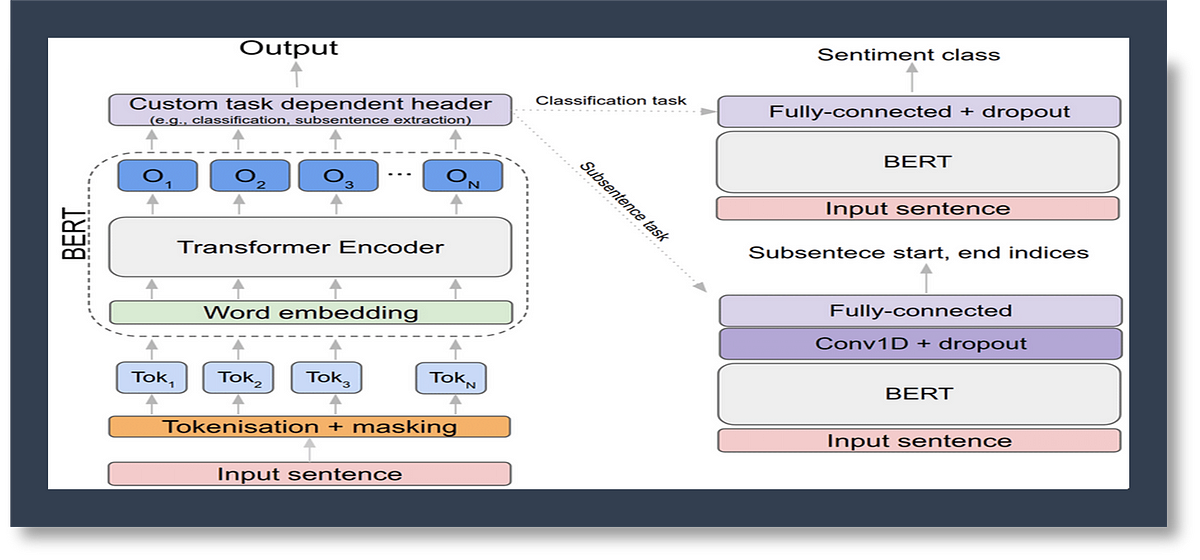
You can fine-tune BERT for tasks like text classification, named entity recognition, and question answering. You can add a small layer to the core model.
Here's a simple example of using BERT for text classification with the Hugging Face Transformers library:
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
text = "This is an example sentence."
inputs = tokenizer(text, return_tensors='pt')
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1)
print(predictions)This code loads a pre-trained BERT model and tokenizer. It then tokenizes an example sentence, feeds it to the model, and gets the model's prediction.
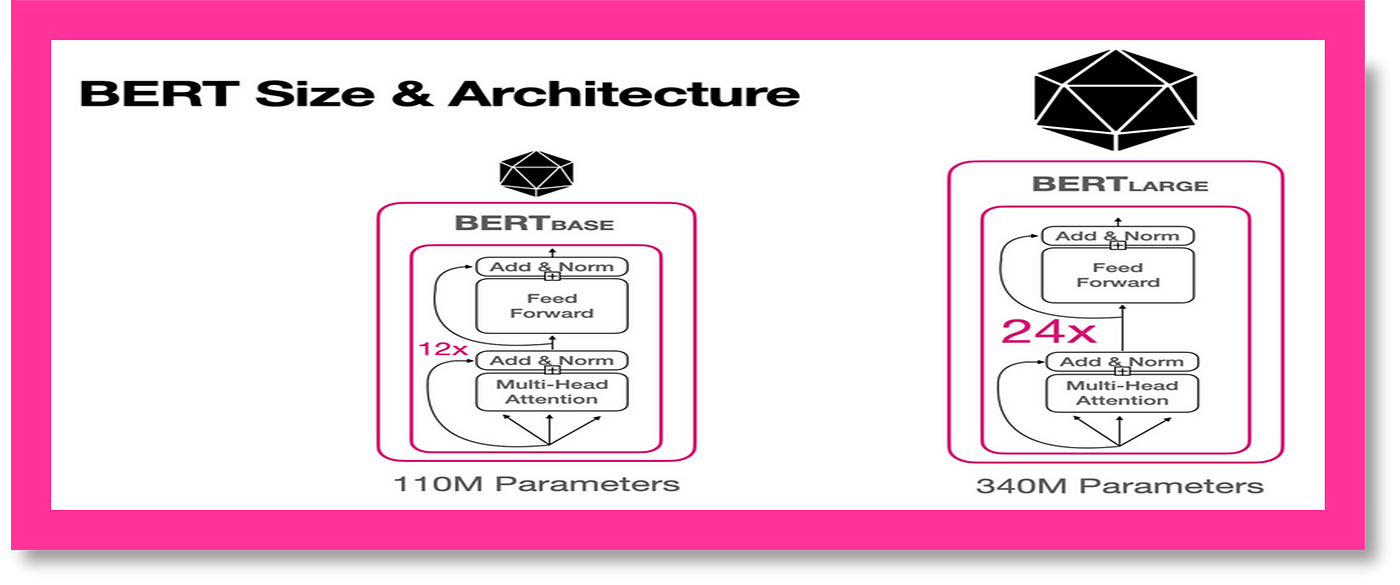
BERT is a large model with millions of parameters. Training it from scratch requires significant computational resources.
Fine-tuning BERT can also be resource-intensive. Especially for large datasets or complex tasks.
BERT has a maximum input sequence length, typically 512 tokens. Handling longer sequences requires special techniques.
Techniques like truncation or sliding window approaches can be used. It is important to know that ModernBERT model has an extended sequence length of 8192.
Future research may focus on developing more efficient versions of BERT. For example, DistilBERT offers a lighter version of BERT; runs 60% faster while maintaining over 95% of BERT’s performance.
Researchers are also exploring ways to improve BERT's performance on specific tasks. It can be done by incorporating external knowledge or using different training strategies.
BERT has had a profound impact on the field of NLP. Its bidirectional training and Transformer architecture have enabled it to achieve state-of-the-art results on a wide range of tasks.
Its ability to understand context and capture complex relationships between words has significantly advanced the state of the art in natural language understanding. For example, BERT helps Google better surface English results for nearly all searches since November of 2020.
While this post provides a beginner-friendly introduction to BERT, there's much more to learn. You can learn more about the Transformer architecture and its applications in NLP.
We encourage you to dive deeper into the original BERT paper, explore the Hugging Face Transformers library, and experiment with fine-tuning BERT for your own tasks. You can also check out the source code and models, which cover 103 languages.
Key Takeaways:
— in Natural Language Processing (NLP)
— in Natural Language Processing (NLP)
— in Deep Learning
— in Natural Language Processing (NLP)
— in GenAI